What is RAG and Why Should You Consider It Over Training Your Own AI Model?
August 15, 2025
The AI landscape has been transforming rapidly over the past few years, and the recent release of GPT-5.0 in August 2025 highlights just how expensive this AI arms race has become. While tech giants continue pouring billions into training increasingly powerful language models, the costs keep escalating – and not everyone needs to join this expensive bandwagon. There's a growing realization that for most use cases, there's a smarter, more accessible way to harness the power of large language models without the astronomical training costs and environmental impact.
Enter Retrieval-Augmented Generation (RAG) – a game-changing approach that’s democratizing AI capabilities for businesses and developers worldwide. And the best part? You can try it yourself right now with our free aiRag tool at sibool.com/build/airag.
What is Retrieval-Augmented Generation?
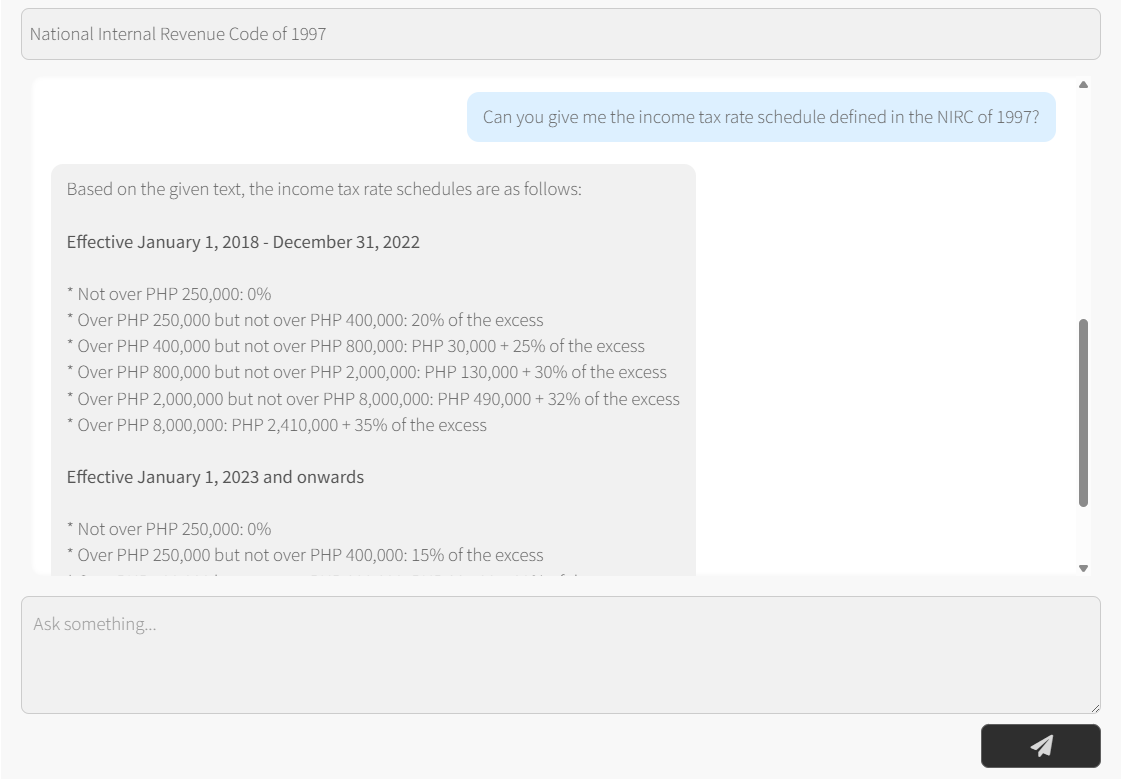
Think of RAG as giving your AI assistant a smart filing cabinet. While traditional large language models (LLMs) like ChatGPT rely solely on their training data — which has a knowledge cutoff date — RAG systems can access and retrieve information from specific documents in real time.
In simple terms, RAG is an advanced form of prompt engineering where the context comes directly from your reference documentation, policies, or any text-based files you provide. Here’s how it works: your reference document gets converted into an nth-dimensional vector database using sophisticated sentence-embedding models like Microsoft’s E5 family. When you ask a question, the system searches through this vector database to find the most relevant information and uses it to construct a more informed response.
Imagine asking an AI about your company’s specific HR policies. A regular LLM might give you generic advice, but a RAG system would pull directly from your actual employee handbook to provide precise, company-specific answers.
RAG vs. Fine-Tuning: The Smart Choice for Most Use Cases
The Fine-Tuning Challenge
- Massive computational requirements: Requires substantial GPU resources and long runtimes.
- High costs: Electricity and hardware can run into tens of thousands of dollars.
- Technical expertise: Needs deep ML knowledge and specialized infra.
- Static knowledge: Frozen until the next fine-tune.
- Data requirements: Demands large, high-quality datasets.
The RAG Advantage
- Cost-effective: No giant GPU clusters; leverage existing LLM APIs.
- Real-time updates: Upload new docs — no retraining needed.
- Transparency: Trace which sources informed answers.
- Accessibility: Implement without deep AI expertise.
- Flexibility: Works with manuals, policies, papers, and more.
- LLM choice freedom: Swap models to balance cost and accuracy.
Who Should Use RAG and Why?
- Legal firms working with case law and regulations
- Healthcare organizations referencing medical guidelines
- Educational institutions creating curriculum-specific tutors
- Corporations needing policy-aware assistants
- Researchers querying large document collections
The magic happens when you have substantial reference materials — think thousand-page PDFs or comprehensive policy manuals. You can’t feed all of that as a plain prompt due to context limits. RAG solves this by retrieving only the most relevant chunks per query, letting the LLM answer accurately with source-backed context.
During inference, RAG constructs prompts that combine your question with the retrieved context, giving the LLM exactly what it needs for precise answers.
Limits and Implementation Considerations
- Quality dependency: Better documents yield better answers.
- Chunking strategy: How you split text affects retrieval quality.
- Embedding quality: Choice of embedding model matters.
- Retrieval precision: Tune to minimize irrelevant pulls.
Try RAG for Free: Introducing aiRag by Sibool
Our aiRag tool demonstrates the power of RAG using a robust stack: FastAPI, LangChain, Hugging Face embeddings, FAISS vector storage, and OpenAI for generation.
How aiRag Works
When you input a question, FAISS retrieves relevant chunks from your vector store; these are combined with your prompt and sent to a language model for accurate, source-aware responses.
Using aiRag: A Step-by-Step Guide
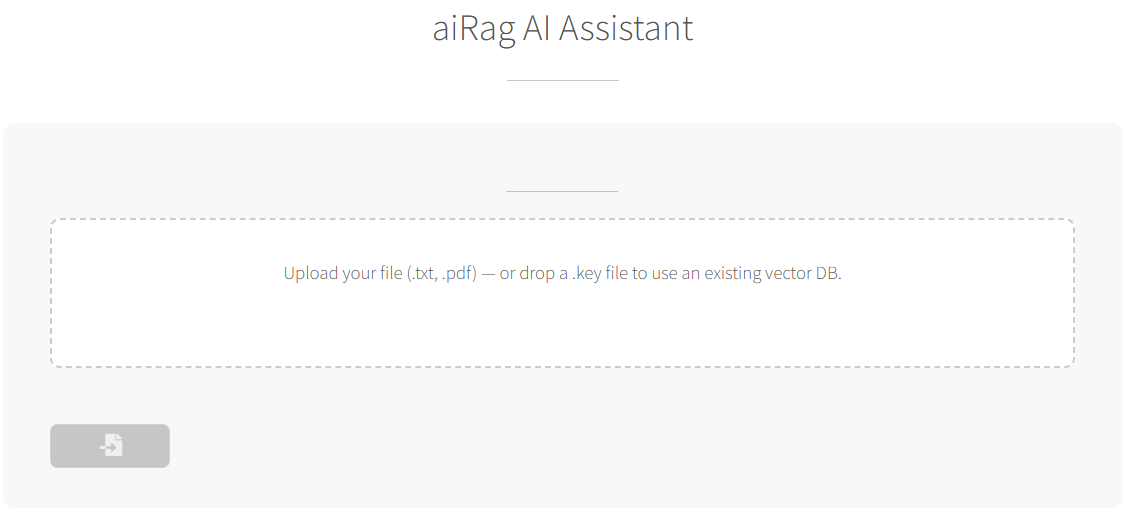
- Access: Visit sibool.com/build/airag
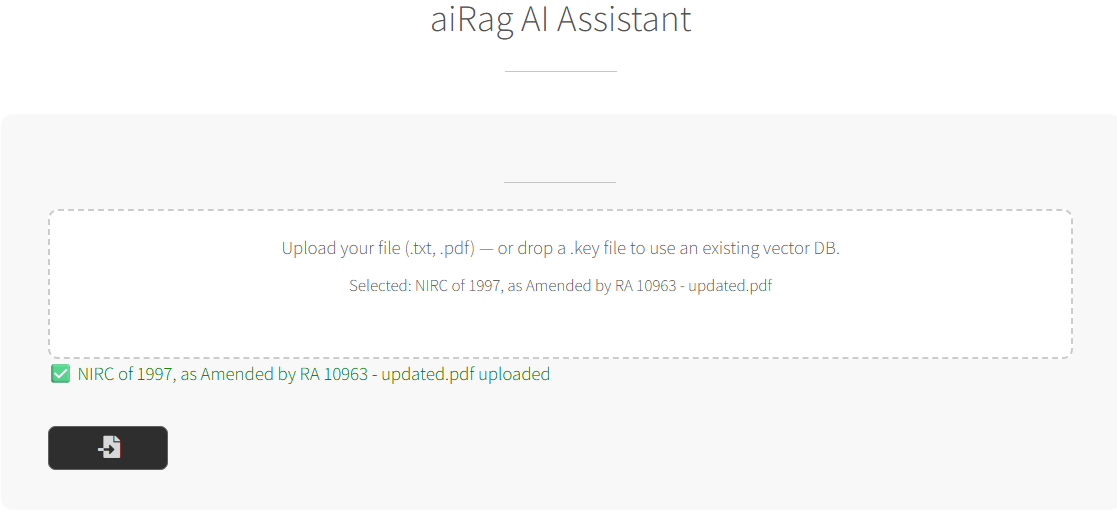
- Upload: Drag and drop your reference document (text-based works best)
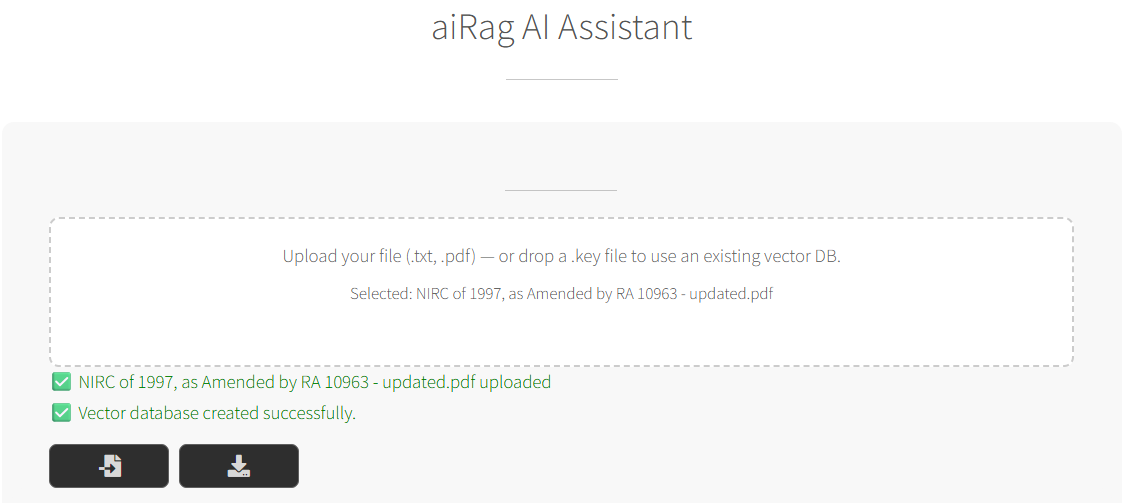
- Convert: Click “Convert” to build the vector database
- Confirm: Look for “Vector database created successfully”
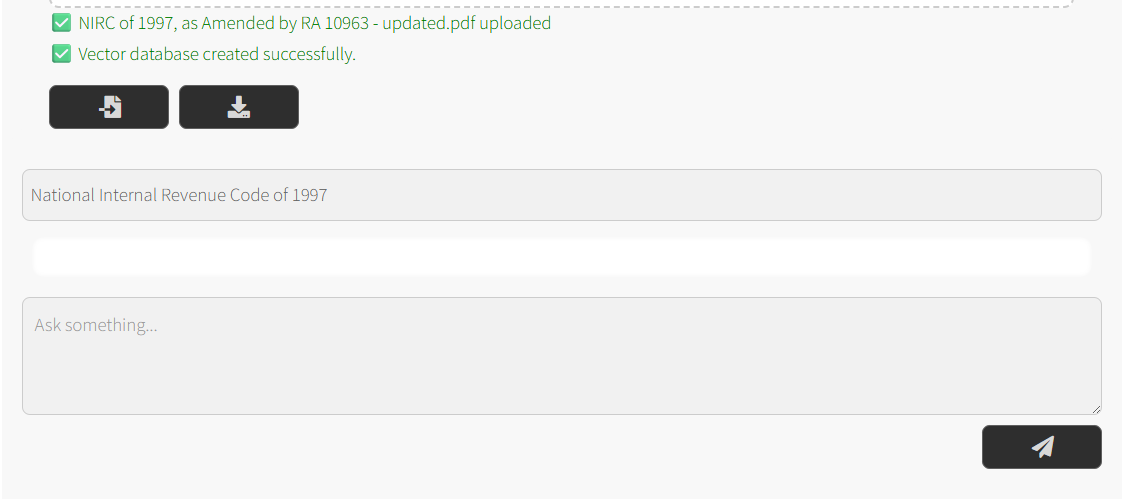
- Set Topic: Start asking questions about your document
- Ask: Start asking questions about your document
Important Note: If you see “No UID Returned,” ensure your document has extractable text; image-only PDFs won’t convert properly.
Technical Highlights
- Backend: Python + LangChain, FAISS, HuggingFace Embeddings
- Frontend: Clean, responsive HTML/CSS/JS
- Deployment: Serverless on RunPod
- AI Integration: OpenAI API for generation
The Future of Accessible AI
RAG shifts the paradigm: instead of training massive models from scratch, enhance powerful LLMs with your own domain knowledge. Ongoing advances — hybrid search (BM25 + vectors), better embeddings, multi-hop reasoning, and improved chat memory — keep raising accuracy.
Conclusion
While the AI world buzzes about ever-bigger models, RAG delivers practical, cost-effective results for real-world apps. Whether you’re a startup, law firm, or educator, RAG pairs state-of-the-art language models with precise, document-aware retrieval.
Try aiRag today at sibool.com/build/airag and see how retrieval-augmented generation can transform your information workflows.